垃圾回收机制
理论知识
垃圾收集器(garbage collector)将内存视为一张有向可达图(reachability graph),其形式如下图
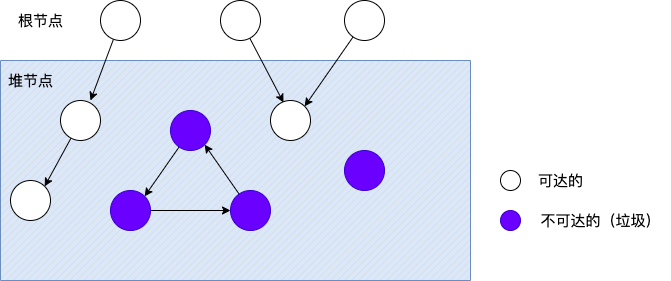
将节点分为根节点(root node) 和堆节点(heap node)。堆节点对应于在堆中的一个已分配块。有向边p -> q 表示p 有对q 的引用。
根节点持有对堆节点内存块的引用,这些根节点可以是寄存器、栈里的变量,或者是虚拟内存中读写数据区域内的全局变量。
当存在一条从任意根节点出发并到达p 的有向路径时,我们说节点p 是 可达的(reachable)。在任何时刻,不可达节点对应于垃圾,
是不能被应用再次使用的。垃圾收集器的角色是维护可达图的某种表示,并通过释放不可达节点且将它们返回给内存管理器(不管是应用的还是系统的),
来定期地回收它们。
综上,垃圾收集器(只针对 Mark&Sweep 标记&清除 算法)需要维护一个已分配的内存块的有向图, 收集操作由 标记(mark) 阶段和 清除(sweep) 阶段组成。
- 标记阶段:
- 遍历节点,找出所有根节点
- 顺着根节点标记出可达的节点。
- 清除阶段:释放每个未被标记为可达的节点。
Python 的垃圾回收机制
Python 使用
- 引用计数
- 分代回收(Generational garbage collector)
两种技术来实现垃圾回收
引用计数
每个Python 对象都有一个ob_refcnt 属性,用来记录引用这个对象的次数,当一个对象的引用被创建或复制时,
引用计数加1;当一个对象的引用被销毁时,引用计数减1。
Python 通过以下的两个 宏 来实现增减引用次数,并在引用次数为零时,调用这个对象的类型对象的析构函数dealloc 进行释放。
#define Py_INCREF(op) ( \
(op)->ob_refcnt++)
#define Py_DECREF(op) \
if (--(op)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(op) \
else \
_Py_Dealloc((PyObject *)(op))
这非常简单,但也带来几个问题:
- 每个对象都多了一个
ob_refcnt属性来占用内存(小问题) - 性能与引用计数的变动次数成正比,每次赋值都需要
++操作(小问题), 引用次数为0时,对于ListDict等对象要遍历所包含的元素,逐个释放(Python 使用了大量内存池机制来弥补) - 直接导致全局解释锁(GIL, Global Interpreter Lock),因为当多线程对同一个全局对象进行增减引用次数并不是原子操作,导致
ob_refcnt结果不正确。 - 循环引用(大问题,需要解决)
当然,也是有优点的:
- 简单,真的很简单
- 实时,引用计数为0就释放。而不是等到内存不够了或时间片用完了,这个时候内存中有大量的已分配对象需要遍历,往往导致程序短暂的停顿。
循环引用
In [1]: l1 = []
In [2]: l2 = []
In [3]: l3 = []
In [4]: l1.append(l2)
In [5]: l2.append(l3)
In [6]: l3.append(l1)
这样就直接导致循环引用,l1.ob_refcnt == 1 l2.ob_refcnt == 1 l3.ob_refcnt == 1 而没有其他变量对这3个对象的引用,
所以引用计数在这种情况下失效了,它检测不出循环引用的存在:显然这三个对象是垃圾(garbage),应该被释放才对。
解决方法
导致这样的主要原因是这3个变量各自的引用计数没有展示出我们希望表现的样子,我们希望这个引用计数应该记录来自外部的引用。 我们希望达到下图的效果:
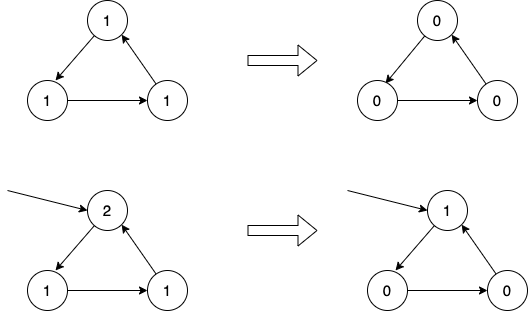
达到这个效果的思路就是: 解铃还须系铃人。既然计数是因为引用才增加的,那么让它再因引用而减少吧。 图的上面那部分中,本来各自的引用计数都为1,遍历container 对象内的引用,使遍历到的对象的引用计数相应减少1。 因此,最后都变成了0。此时,可以将上面三个变量标记为 不可达的。
而图的下面那部分中,因为有一个来自外部的引用,因此在经过一轮container 对象内的引用遍历后,上顶角的对象的引用计数为1 (外部的引用在对象内遍历不到),因此可以暂时把两个底角上的对象标记为 不可达的,而顶角的对象依旧是 可达的。
这样我们就将一个有向图中的所有节点分成 可达的 和 不可达的 两类。 而对于 可达的 对象,它所引用的对象也应该是 可达的, 对应图的下半部分中,虽然底角的对象被标记为 不可达的,但是因为有 可达的 对象的引用, 因此,还需要再遍历一遍 可达的 对象所引用的对象,将它们都设置为可达的。
综上,总结为以下几步:
- 遍历所有节点,对每个节点,使这个节点所引用对象的引用次数减1
- 再遍历一遍所有节点,根据节点的引用次数将这些节点分为 可达的 和 不可达的 两类
伪代码如下:
for node in {n0, n1, n2...}:
for element in node:
element.ob_refcnt -= 1
for node in {n0, n1, n2...}:
if node.ob_refcnt == 0 and node not mark reachable:
mark node as unreachable
if node.ob_refcnt > 0:
mark node as reachable
for element in node:
mark element as reachable
通过上面的方法,我们就判断出哪些对象是因为循环引用而没被引用计数回收的,接下来就只要对这些对象进行清理就行了。
分代回收(Generational garbage collector)
Given a realistic amount of memory, efficiency of simple copying garbage collection is limited by the fact that the system must copy all live data at a collection. In most programs in variety of languages, most objects live a very short time, while a small percentage of then live much longer. While figures vary from language to language and program to program, usually between 80 and 98 precent of all newly-allocated heap objects die within a few million instructions, or before another megabyte has been allocated; the majority of objects die even more quickly, within tens of kilobytes of allocation.
上面是说:大多数对象的寿命都很短,只有一小部分的对象寿命比较长,通常在所有新分配的对象中,有80%到98%在几百万条指令内就死亡(成为垃圾)了。
这也是很直观的,在函数调用中,除了出、入参数外,大部分的局部变量、临时变量都可以在这次调用后被销毁、回收。 而那些在主函数中声明的变量、全局变量的生命周期往往和程序相同。
分代回收机制正是基于上面的事实。其总体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合称为一个“代”, 垃圾回收的频率随着“代”的存活时间的增大而减小,也就是说,活得越长的对象,就越不可能是垃圾,就应该越少去收集。
源码分析
维护一个有向图
无非就是链表、双向链表或者树的结构,Python 实现中使用的双向链表。
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
因为这个机制是只针对循环引用的,而循环引用只发生在 container 容器对象,如List Dict class等中,而int str 等对象是不可能发生循环引用的。
因此,上面结构只需要给container对象加上即可。如图:
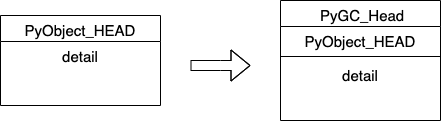
在原来的基础上带了个gc head 的 帽子,表示这是一个需要gc 监控的container 对象。
在创建每个container 对象时,Python 使用PyObject_GC_New,而创建非container 对象时则使用PyObject_Malloc。
PyObject *
_PyObject_GC_Malloc(size_t basicsize)
{
PyObject *op;
PyGC_Head *g = (PyGC_Head *)PyObject_MALLOC(sizeof(PyGC_Head) + basicsize);
g->gc.gc_refs = GC_UNTRACKED;
...
return op;
}
PyObject *
_PyObject_GC_New(PyTypeObject *tp)
{
PyObject *op = _PyObject_GC_Malloc(_PyObject_SIZE(tp));
if (op != NULL)
op = PyObject_INIT(op, tp);
return op;
}
PyObject_GC_New 只是调用PyObject_Malloc 多分配一个PyGC_Head 结构大小的内存。
/* Get an object's GC head */
#define AS_GC(o) ((PyGC_Head *)(o)-1)
/* Get the object given the GC head */
#define FROM_GC(g) ((PyObject *)(((PyGC_Head *)g)+1))
这两个 宏 通过加减一个PyGC_Head 结构大小来实现PyObject 和PyGC_Head 之间的切换。
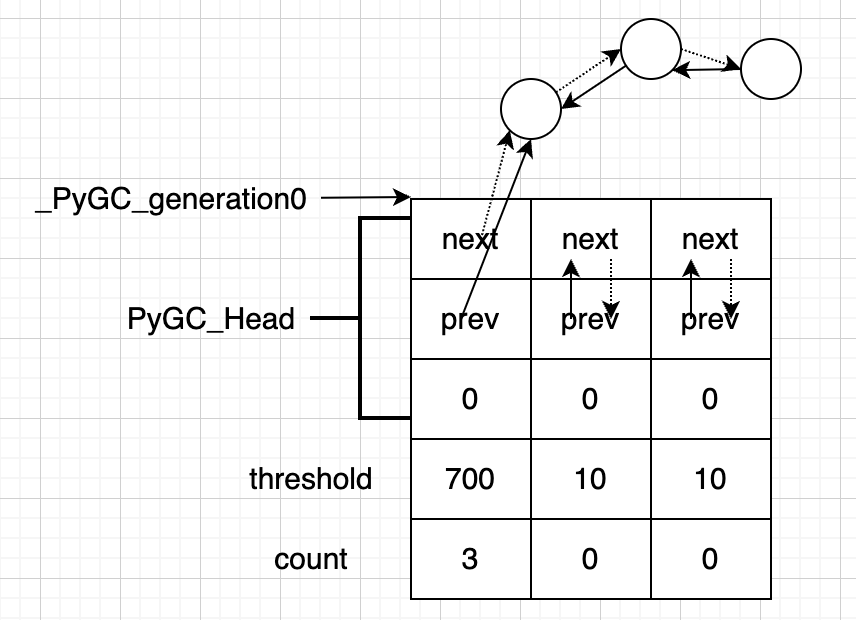
struct gc_generation {
PyGC_Head head;
int threshold; /* 这一“代”的最大阈值,当count >= threshold 时就对这“代”进行垃圾回收 */
int count; /* 对于第0代而言,count 表示进行分配的次数,而对于更高的代来说,表示的是在这代上进行collect(i) 的次数 */
};
#define NUM_GENERATIONS 3
#define GEN_HEAD(n) (&generations[n].head)
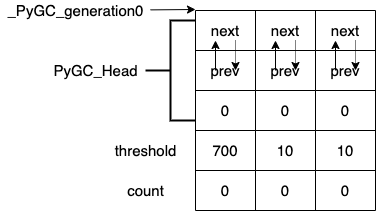
static struct gc_generation generations[NUM_GENERATIONS] = {
{ { { GEN_HEAD(0), GEN_HEAD(0), 0 } }, 700, 0}, /* 称为“青生代” */
{ { { GEN_HEAD(1), GEN_HEAD(1), 0 } }, 10, 0}, /* 称为“中生代” */
{ { { GEN_HEAD(2), GEN_HEAD(2), 0 } }, 10, 0}, /* 称为“老生代” */
};
PyGC_Head *_PyGC_generation0 = GEN_HEAD(0);
这就是“有向图”的结构,也是其称为分代回收的原因。从上面代码上可以看出它分为3代。每一代都是一个双向链表的结构。 它的初始状态,如图:
/* 简单的双向列表操作,将对象`o` 加入到`_PyGC_generation0` “青生代”中*/
#define _PyObject_GC_TRACK(o) do { \
PyGC_Head *g = _Py_AS_GC(o); \
g->gc.gc_refs = _PyGC_REFS_REACHABLE; \
g->gc.gc_next = _PyGC_generation0; \
g->gc.gc_prev = _PyGC_generation0->gc.gc_prev; \
g->gc.gc_prev->gc.gc_next = g; \
_PyGC_generation0->gc.gc_prev = g; \
} while (0);
加入若干container 对象后,“有向图”可能长这样:
随着不断的创建container 对象,
/* true if we are currently running the collector */
static int collecting = 0;
PyObject *
_PyObject_GC_Malloc(size_t basicsize)
{
PyObject *op;
PyGC_Head *g = (PyGC_Head *)PyObject_MALLOC(sizeof(PyGC_Head) + basicsize);
g->gc.gc_refs = GC_UNTRACKED;
generations[0].count++; /* number of allocated GC objects */
if (generations[0].count > generations[0].threshold &&
enabled &&
generations[0].threshold &&
!collecting &&
!PyErr_Occurred()) {
collecting = 1;
collect_generations(); /* 进行垃圾回收 */
collecting = 0;
}
op = FROM_GC(g);
return op;
}
变量collecting 是一个全局的变量标识当前Python 解释器是否在进行垃圾回收(因为GIL存在,所以无所谓变量可不可重入)。
可以看到,当generations[0].count > generations[0].threshold 的时候,就调用collect_generations()进行垃圾回收。
标记阶段
static Py_ssize_t
collect_generations(void)
{
int i;
Py_ssize_t n = 0;
/* 从最老的“代”开始重新判断要从哪个代开始回收 */
for (i = NUM_GENERATIONS-1; i >= 0; i--) {
if (generations[i].count > generations[i].threshold) {
n = collect(i);
break;
}
}
return n;
}
上面的函数找出满足count 值越界的最“老”的那一“代”,对这“代”进行收集(collect)操作。因为,“代”上的结构是双向链表,
因此,就可以应用 循环引用的解决方法 进行垃圾标记和回收。
Python 实现中先将比要收集的“代”要年轻的“代”都合并到这“代”上(相当于让年轻的“代”变老),假设对1代 进行收集,这将0代 合到1代 上。
/* 简单的链表操作将两条双向链表合并 */
static void
gc_list_merge(PyGC_Head *from, PyGC_Head *to)
{
PyGC_Head *tail;
if (!gc_list_is_empty(from)) {
tail = to->gc.gc_prev;
tail->gc.gc_next = from->gc.gc_next;
tail->gc.gc_next->gc.gc_prev = tail;
to->gc.gc_prev = from->gc.gc_prev;
to->gc.gc_prev->gc.gc_next = to;
}
gc_list_init(from);
}
在得到要处理的有向图(双向链表)后,Python 先遍历一边这“代”上要进行收集的对象,将对象的ob_refcnt 赋值给PyGC_Head.gc_refs ,
防止在接下来的操作中对ob_refcnt 产生副作用。
static void
update_refs(PyGC_Head *containers)
{
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc = gc->gc.gc_next) {
gc->gc.gc_refs = FROM_GC(gc)->ob_refcnt;
}
}
接下来就是解决循环引用的关键了:遍历所有节点,对每个节点,使这个节点所引用对象的引用次数减1。
static void
subtract_refs(PyGC_Head *containers)
{
traverseproc traverse;
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc=gc->gc.gc_next) {
traverse = FROM_GC(gc)->ob_type->tp_traverse;
(void) traverse(FROM_GC(gc), (visitproc)visit_decref, NULL);
}
}
每个Python 对象的类型对象都有一个tp_traverse 的函数指针,这个函数实现遍历这个对象所包含的对象,并调用回调函数visit_decref ,
将每个对象的gc_refs 减1。
static int
visit_decref(PyObject *op, void *data)
{
if (PyObject_IS_GC(op)) {
PyGC_Head *gc = AS_GC(op);
if (gc->gc.gc_refs > 0)
gc->gc.gc_refs--;
}
return 0;
}
经过subtract_refs 函数后,这“代”上所有的container 对象的gc_refs 都 >=0,并且可以断定那些gc_refs > 0 的对象就一定是 可达的,
也就是不可以被收集的,可以叫做这“代”上的根节点(root node)。
然后,再遍历一遍所有节点,根据节点的引用次数将这些节点分为 可达的 和 不可达的 两类。
Python 初始化一个双向链表unreachable,将在这遍中判断出来的 不可达的 对象链接到该链表上来实现。
static void
move_unreachable(PyGC_Head *young, PyGC_Head *unreachable)
{
PyGC_Head *gc = young->gc.gc_next;
while (gc != young) {
PyGC_Head *next;
if (gc->gc.gc_refs) {
PyObject *op = FROM_GC(gc);
traverseproc traverse = op->ob_type->tp_traverse;
gc->gc.gc_refs = GC_REACHABLE;
(void) traverse(op, (visitproc)visit_reachable, (void *)young);
next = gc->gc.gc_next;
} else {
next = gc->gc.gc_next;
gc_list_move(gc, unreachable);
gc->gc.gc_refs = GC_TENTATIVELY_UNREACHABLE;
}
gc = next;
}
}
可以看到,Python 遍历这“代”上的所有对象,如果gc_refs > 0 就将该对象标记为GC_REACHABLE ,
并且调用该对象的类型对象的遍历函数,使用回调函数visit_reachable 进行处理。
如果gc_refs == 0 则将它移到unreachable 中,标记为GC_TENTATIVELY_UNREACHABLE。
static int
visit_reachable(PyObject *op, PyGC_Head *reachable)
{
if (PyObject_IS_GC(op)) {
PyGC_Head *gc = AS_GC(op);
const Py_ssize_t gc_refs = gc->gc.gc_refs;
if (gc_refs == 0) {
gc->gc.gc_refs = 1;
} else if (gc_refs == GC_TENTATIVELY_UNREACHABLE) {
gc_list_move(gc, reachable);
gc->gc.gc_refs = 1;
} else {
assert(gc_refs > 0 || gc_refs == GC_REACHABLE || gc_refs == GC_UNTRACKED);
}
}
return 0;
}
这个代码和我上面写的伪代码的思路有点不一样。Python 的实现中是又使用了一个标记GC_TENTATIVELY_UNREACHABLE,
表示这个对象 暂时(TENTATIVELY) 是 不可达的,之后在遍历 可达的 对象时,
如果 可达的 对象引用了一个标记为GC_TENTATIVELY_UNREACHABLE的对象,则这个对象就变成 可达的 了,
并把它移出 不可达的 链表unreachable。
至此,我们就将这“代”上的 垃圾 分离到unreachable 上了,该链表上的对象就是 可收集的(collectable),
接下来就可以在这个双向链表上进行清理工作了。
清除阶段
static void
delete_garbage(PyGC_Head *collectable, PyGC_Head *old)
{
inquiry clear;
while (!gc_list_is_empty(collectable)) {
PyGC_Head *gc = collectable->gc.gc_next;
PyObject *op = FROM_GC(gc);
if ((clear = op->ob_type->tp_clear) != NULL) {
Py_INCREF(op); // 将循环引用的对象先加1,防止在调用`dealloc` 的时候导致`ob_refcnt` 变成负数
clear(op);
Py_DECREF(op);
}
if (collectable->gc.gc_next == gc) {
/* object is still alive, move it, it may die later */
/* 所以什么时候会发生这种情况呢??? */
gc_list_move(gc, old);
gc->gc.gc_refs = GC_REACHABLE;
}
}
}
然后对于每个可回收的对象调用它的类型对象的tp_clear 方法。对于List 如下:
static int
list_clear(PyListObject *a)
{
Py_ssize_t i;
PyObject **item = a->ob_item;
if (item != NULL) {
i = a->ob_size;
a->ob_size = 0;
a->ob_item = NULL; // 设为NULL,在`dealloc` 中跳过判定
a->allocated = 0;
while (--i >= 0) {
Py_XDECREF(item[i]);
}
PyMem_FREE(item);
}
return 0;
}
将该List 的参数信息都置为零,并且遍历List 中的对象,将它的引用计数ob_refcnt 减1。因为这个是有循环引用的对象,
因此,这里面的某个item[i] 就是循环引用该对象的对象,这个时候将它的引用计数减1后,可能就触发了引用计数的收集机制,
因此,可能就会调用该对象的析构函数(dealloc),List 的如下:
static void
list_dealloc(PyListObject *op)
{
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (op->ob_item != NULL) {
i = op->ob_size;
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
if (num_free_lists < MAXFREELISTS && PyList_CheckExact(op))
free_lists[num_free_lists++] = op;
else
op->ob_type->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
析构函数的操作和clear 函数的差不多,就多了一个从垃圾回收链表中摘除该元素的操作。
这个 宏 就是之前_PyObject_GC_TRACK 的逆操作。
#define _PyObject_GC_UNTRACK(o) do { \
PyGC_Head *g = _Py_AS_GC(o); \
assert(g->gc.gc_refs != _PyGC_REFS_UNTRACKED); \
g->gc.gc_refs = _PyGC_REFS_UNTRACKED; \
g->gc.gc_prev->gc.gc_next = g->gc.gc_next; \
g->gc.gc_next->gc.gc_prev = g->gc.gc_prev; \
g->gc.gc_next = NULL; \
} while (0);
这样,这个container 清空自己用来存储所有引用对象指针的内存,并且将自己放回到空闲链表中。
用上面的例子再说明下,
In [1]: l1 = []
In [2]: l2 = []
In [3]: l1.append(l2)
In [4]: l2.append(l1)
l1 l2 就被链接在collectable 中,假设delete_garbage 中先遍历到l1 ,
-> Py_INCREF(l1) # l1.ob_refcnts == 2
-> list_clear(l1)
-> l1.ob_item = NULL
-> Py_XDECREF(l2) # l2.ob_refcnts == 0
-> list_dealloc(l2)
-> Py_XDECREF(l1) # l1.ob_refcnts == 1
-> PyMem_FREE(l2)
-> add to free_lists
-> PyMem_FREE(item)
-> Py_DECREF(l1)
-> list_dealloc(l1)
-> add to free_lists
需要注意的是,这个时候l1 的引用计数先加了1,否则在调用l2 的dealloc 时l1 的引用计数就变成0了,
触发l1 的dealloc 就会使l2 的引用计数变为负数,则报错。
全流程
下面的函数即是垃圾回收的主函数。
static Py_ssize_t
collect(int generation)
{
int i;
PyGC_Head *young;
PyGC_Head *old;
PyGC_Head unreachable; /* **不可达的** 对象链表 */
PyGC_Head *gc;
/* update collection and allocation counters */
/* 这里的count 记录的并不是在这个“代”的双向链表中链接了多少个对象(这通过gc_list_size得到),
* 而是这个“代”经历了多少次的collect */
/* (700, 10, 10) 意味着每进行700次的分配就进行一次collect(0) 使得第一“代”的 count+=1,
* 每进行700*10 次分配就进行一次collect(1)使得第二代的count+=1
* 每进行700*10*10 次分配进行一次collect(2),将所有代的重新置零 */
if (generation+1 < NUM_GENERATIONS)
generations[generation+1].count += 1;
for (i = 0; i <= generation; i++)
generations[i].count = 0;
/* 将比要收集的“代”要年轻的“代”都合并到这“代”上 */
for (i = 0; i < generation; i++) {
gc_list_merge(GEN_HEAD(i), GEN_HEAD(generation));
}
young = GEN_HEAD(generation);
if (generation < NUM_GENERATIONS-1)
old = GEN_HEAD(generation+1);
else
old = young;
/* 遍历所有节点,对每个节点,使这个节点所引用对象的引用次数减1 */
update_refs(young);
subtract_refs(young);
/* 再遍历一遍所有节点,根据节点的引用次数将这些节点分为**可达的** 和**不可达的** 两类 */
gc_list_init(&unreachable);
move_unreachable(young, &unreachable);
/* 将这“代”上的对象移到更老的一代上去 */
if (young != old)
gc_list_merge(young, old);
...
/* 进行清除 */
delete_garbage(&unreachable, old);
...
}
至此,终于将Python 的垃圾回收机制码完了。
总结
分代垃圾回收的优点
参考
源码文件:
Include/object.hInclude/objimpl.hModules/gcmodule.c
《Python源码剖析》
Garbage Collection for Python
Wilson-GC