Python Dict对象解析
散列表
嗯,基本面试的时候都会问一下散列表,基本就回答下解决冲突的几种方法:
- 分离链接法
- 开放定址法
- 再散列
巴拉巴拉,就敷衍过去了,(* ̄︶ ̄)
情景分析
和在
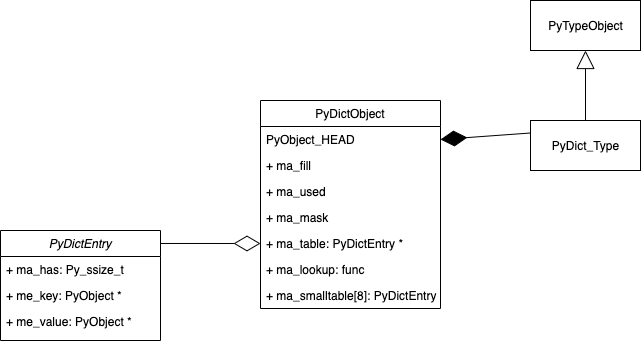
Python对象机制基石——PyObject
中讲的差不多,dict 在源码里是就是由PyDictObject 和类型对象PyDict_Type 实现的。
note: 这里我把c 中的struct 直接抽象成了类图。
冲突解决策略
Python 采用的冲突解决方案是 开放定址法 ,当产生散列冲突时,Python 会通过一个二次探测函数f ,
计算下一个候选位置addr ,如果位置可用,则将待插入的元素放在该位置。否则,再次使用探测函数f 计算下一个候选位置,
如此不断探测。最坏情况下,遍历完整个分配的散列表,找到一个可用的位置。
这个探测函数f 由两个变量所控制: 1. 输入值的hash 值 2. 散列表当前的长度, 可以写成
f(hash, len(table)) -> [0, len(table) - 1]
所以当出现冲突时,相同的hash 值就对应了一条“ 冲突探测链 ”。看似已经很完善了,但是当删除这条探测链上的某个元素时,问题就产生了。
如下图的情况:
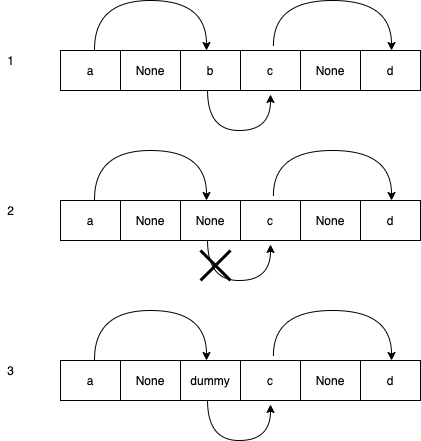
一开始有一条 冲突探测链 a -> b -> c -> d,当我们删除元素b ,如果简单的将原来b 位置设置为None ,那么就无法访问到c 和d 了。
因为,从a 出发,探测函数计算出的下一个候选位置被设置成了None ,被认为是到达了结尾,因此直接返回了。
因此,删除元素时,不能进行真正的删除,而是进行一种“伪删除”操作。Python 通过引入三种状态的entry 来解决这个问题。如下图:
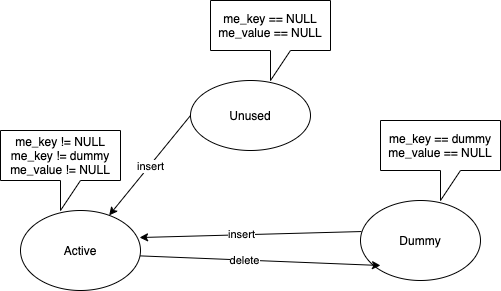
- Unused: 每个元素的初始状态,表示到目前为止,该
entry都没有存储过(key, value)对。 - Active: 该
entry存储的(key, value)对是可用的。 - Dummy: 这个就是为了解决上面提到的问题所采取的措施,将一个被删除的元素设置为
Dummy,这样当我们沿着冲突链查找元素时, 当遇到状态为Dummy的entry时,可以继续搜索而不至于停止。
动态表
也有说是 再散列 的,当装载因子大于某个值后,就进行扩容,将原来的项 再散列 到新的表中。
和list 不同,dict 的动态扩张不止是为了其装载因子为1时进行自动扩张,
最主要的是保持dict 的装载因子在某个值之下, 从而使得散列冲突发生的概率减小。
Python-2.5.1 中将这个装载因子设置为 2/3。
源码分析
有了上面的“需求”和“解决方案”后,我们就可以看下代码是怎么实现的了。
元素搜索
#define PERTURB_SHIFT 5
static PyObject *dummy = PyString_FromString("<dummy key>"); /* 嗯,`Dummy` 其实就是一个字符串 */
static dictentry *
lookdict(dictobject *mp, PyObject *key, register long hash)
{
register size_t i;
register size_t perturb;
// 记录在冲突链上第一个Dummy 的entry,返回直接可用于insert
register dictentry *freeslot;
register size_t mask = (size_t)mp->ma_mask;
dictentry *ep0 = mp->ma_table;
register dictentry *ep;
register int cmp;
PyObject *startkey;
/** 处理第一个entry **/
// 简单的将hash map到size 为me_mask 的数组表内
i = (size_t)hash & mask;
ep = &ep0[i];
// 第一个entry 为`Unused` 或者找到对应的key 就返回(key 相等表示的是引用的是同一个对象)
// 但对于int 而言,d[1000] = 'hstk', 每次生成的`1000` 所指向的对象并不是同一个,因此,
// 下面还要进行 值的比较
if (ep->me_key == NULL || ep->me_key == key)
return ep;
if (ep->me_key == dummy)
freeslot = ep; // 记录Dummy 态entry
else {
if (ep->me_hash == hash) {
startkey = ep->me_key;
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ); // 值的比较
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep; // 找到对应key 的entry ,返回
}
else {
return lookdict(mp, key, hash);
}
}
freeslot = NULL;
}
/** 处理哈希冲突链上剩下的entry **/
for (perturb = hash; ; perturb >>= PERTURB_SHIFT) {
// 二次探测函数计算下一个位置
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
// 到达`Unused` 态entry,表示搜索失败
if (ep->me_key == NULL)
/* 如果freeslot 不为空,则返回处于`Dummy` 态的entry,而不是处于`Unused` 态的entry,
供insert 使用,这样下次这个hash 再冲突时保证这之前的链上没有`Dummy` 态的entry */
return freeslot == NULL ? ep : freeslot;
// 引用相同?
if (ep->me_key == key)
return ep;
// 哈希相同,值相同?
if (ep->me_hash == hash && ep->me_key != dummy) {
startkey = ep->me_key;
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
if (cmp < 0)
return NULL;
if (ep0 == mp->ma_table && ep->me_key == startkey) {
if (cmp > 0)
return ep;
}
else {
return lookdict(mp, key, hash);
}
}
else if (ep->me_key == dummy && freeslot == NULL)
// 记录freeslot
freeslot = ep;
}
assert(0); /* NOT REACHED */
return 0;
}
可以总结为1:
- 根据hash 值获得entry 的索引,这是冲突探测链上第一个entry 的索引。
- 在两种情况下,搜索结束:
- entry 处于
Unused态,表明冲突探测链搜索完成,搜索失败。 ep->me_key == key,表明entry 的key 与带搜索的key 匹配,搜索成功。
- entry 处于
- 若当前entry 处于
Dummy态,设置freeslot。 - 检查
Active态entry 中的key 与待查找的key 是否“值相等”,若成立,搜索成功。 - 根据
Python所采用的探测函数,获得探测链中的下一个待检查的entry。 - 检查到一个
Unused态entry,表明搜索失败,这时有两种结果:- 如果
freeslot不为空,则返回freeslot所指entry。 - 如果
freeslot为空,则返回该Unused态entry。
- 如果
- 检查entry 中的key 与待查找的key 是否符合“引用相同”规则。
- 检查entry 中的key 与待查找的key 是否符合“值相同”规则。
- 在遍历过程中,如果发现
Dummy态entry,且freeslot未设置,则设置freeslot。
元素插入、删除
static int
insertdict(register dictobject *mp, PyObject *key, long hash, PyObject *value)
{
PyObject *old_value;
register dictentry *ep;
// 搜索key
ep = lookdict(mp, key, hash);
// 搜索成功,对应key 已经存在在dict 中,简单的修改value 即可
if (ep->me_value != NULL) {
old_value = ep->me_value;
ep->me_value = value;
}
// 搜索失败,对应的ep 可以是`Unused` 或`Dummy` 态的entry,设置对应的key, value 就完事了
else {
if (ep->me_key == NULL)
mp->ma_fill++; //
else {
Py_DECREF(dummy);
}
ep->me_key = key;
ep->me_hash = (Py_ssize_t)hash;
ep->me_value = value;
mp->ma_used++;
}
return 0;
}
真正的dict.__setitem__() 对应下面的c 函数
int
PyDict_SetItem(register PyObject *op, PyObject *key, PyObject *value)
{
register dictobject *mp;
register long hash;
register Py_ssize_t n_used;
// 计算key 的hash
hash = PyObject_Hash(key);
n_used = mp->ma_used;
// 插入元素
if (insertdict(mp, key, hash, value) != 0)
return -1;
// 是否需要动态扩张或收缩dict
if (!(mp->ma_used > n_used && mp->ma_fill*3 >= (mp->ma_mask+1)*2))
return 0;
return dictresize(mp, (mp->ma_used > 50000 ? 2 : 4) * mp->ma_used);
}
删除操作
int
PyDict_DelItem(PyObject *op, PyObject *key)
{
register dictobject *mp;
register long hash;
register dictentry *ep;
PyObject *old_value, *old_key;
hash = PyObject_Hash(key);
mp = (dictobject *)op;
// 搜索key
ep = (mp->ma_lookup)(mp, key, hash);
// 搜索失败
if (ep == NULL)
return -1;
if (ep->me_value == NULL) {
set_key_error(key);
return -1;
}
// 搜索成功,“伪删除”对应的entry
old_key = ep->me_key;
ep->me_key = dummy;
old_value = ep->me_value;
ep->me_value = NULL;
mp->ma_used--;
return 0;
}
一切都变得非常简单 ^_^
动态表的扩张和收缩
在PyDict_SetItem 的最后:
if (!(mp->ma_used > n_used && mp->ma_fill*3 >= (mp->ma_mask+1)*2))
return 0;
// 装载因子大于2/3 时, 将表的大小设置为ma_used 的2 或4 倍
return dictresize(mp, (mp->ma_used > 50000 ? 2 : 4) * mp->ma_used);
这里说明下三个统计字段的含义:
PyDictObject->ma_used: 处于Active态entry 的个数PyDictObject->ma_fill: 处于Active和Dummy态的个数PyDictObject->ma_mask: 当前表的大小,为2 的倍数
需要注意的是,这里是按ma_used 计算新表的大小的,如果原来的dict 有过很多的删除操作,也就是存在大量Dummy 态entry,
这时,表的大小会收缩而不是扩张。
static int
dictresize(dictobject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
dictentry *oldtable, *newtable, *ep;
Py_ssize_t i;
/* 找到大于minused 的最小的以2位倍数的size */
for (newsize = PyDict_MINSIZE;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
// 为新表申请相应大小的内存
newtable = PyMem_NEW(dictentry, newsize);
// 设置新表的信息
mp->ma_table = newtable;
mp->ma_mask = newsize - 1;
memset(newtable, 0, sizeof(dictentry) * newsize);
mp->ma_used = 0;
i = mp->ma_fill;
mp->ma_fill = 0;
// 遍历旧表,将旧表中Active 态entry 一个个插入新表中
for (ep = oldtable; i > 0; ep++) {
if (ep->me_value != NULL) { /* active entry */
--i;
insertdict_clean(mp, ep->me_key, (long)ep->me_hash,
ep->me_value);
}
else if (ep->me_key != NULL) { /* dummy entry */
--i;
Py_DECREF(ep->me_key);
}
/* else key == value == NULL: nothing to do */
}
return 0;
}
以上代码片段都是在源代码的基础上删除了很多的异常检查判断(dictresize 中还删除了处理smalltable 的代码),
但是相信总的结构是没有改变的。
源码文件
Python-2.5.1:
- Include/dictobject.h
- Objects/dictobject.c
cPython-3.6:
- Include/cpython/dictobject.h
- Objects/dictobject.c
- Objects/clinic/dictobject.c.h
cPython-3.6 中的实现
The dict type has been reimplemented to use a more compact representation based on a proposal by Raymond Hettinger and similar to the PyPy dict implementation. This resulted in dictionaries using 20% to 25% less memory when compared to Python 3.5. 2
cPython-3.6 中对我们这里将的dict 进行了一次大的改进,有空再去学习一下。也可以看一下这个老哥写的cPython-Internals-dict,里面讲的就是新的dict 的实现细节。
–
找到一篇大佬
Raymond Hettinger
写的
PROOF-OF-CONCEPT FOR A MORE SPACE-EFFICIENT, FASTER-LOOPING DICTIONARY。
用Python 实现新型dict ,原来大佬12年就提出来了,结果16年才正式添加到cPython 里。
这个Python 实现写的非常清晰,不在话下。
-
《Python源码剖析》 ↩